
Different statistical algorithms have been developed to implement association rule mining, and Apriori is one such algorithm.
In this lab we will study the theory behind the Apriori Algorithm and will later implement Apriori algorithm in Python.
There are three major components of Apriori algorithm:
1. SupportWe will explain these three concepts with the help of an example.
Suppose we have a record of 1 thousand customer transactions, and we want to find the Support, Confidence, and Lift for two items e.g. burgers and ketchup.
Out of one thousand transactions, 100 contain ketchup while 150 contain a burger.
Out of 150 transactions where a burger is purchased, 50 transactions contain ketchup as well.
Using this data, we want to find the support, confidence, and lift.
Support
Support refers to the default popularity of an item and can be calculated by finding number of transactions containing a particular item divided by total number of transactions. Suppose we want to find support for item B. This can be calculated as:
|
Support(B) = (Transactions containing (B))/(Total Transactions) |
For instance if out of 1000 transactions, 100 transactions contain Ketchup then the support for item Ketchup can be calculated as:
|
Support(Ketchup) = (Transactions containingKetchup)/(Total Transactions) Support(Ketchup) = 100/1000 = 10% |
Confidence
Confidence refers to the likelihood that an item B is also bought if item A is bought. It can be calculated by finding the number of transactions where A and B are bought together, divided by total number of transactions where A is bought. Mathematically, it can be represented as:
|
Confidence(A→B) = (Transactions containing both (A and B))/(Transactions containing A) |
Coming back to our problem, we had 50 transactions where Burger and Ketchup were bought together.
While in 150 transactions, burgers are bought.
Then we can find likelihood of buying ketchup when a burger is bought can be represented as confidence of Burger -> Ketchup and can be mathematically written as:
|
Confidence(Burger→Ketchup) = (Transactions containing both (Burger and Ketchup))/(Transactions containing A) Confidence(Burger→Ketchup) = 50/150 = 33.3% |
You may notice that this is similar to what you'd see in the Naive Bayes Algorithm, however, the two algorithms are meant for different types of problems.
Lift
Lift(A -> B) refers to the increase in the ratio of sale of B when A is sold. Lift(A –> B) can be calculated by dividing Confidence(A -> B) divided by Support(B). Mathematically it can be represented as:
|
Lift(A→B) = (Confidence (A→B))/(Support (B)) |
Coming back to our Burger and Ketchup problem, the Lift(Burger -> Ketchup) can be calculated as:
|
Lift(Burger→Ketchup) = (Confidence (Burger→Ketchup))/(Support (Ketchup)) Lift(Burger→Ketchup) = 33.3/10 = 3.33 |
Lift basically tells us that the likelihood of buying a Burger and Ketchup together is 3.33 times more than the likelihood of just buying the ketchup.
A Lift of 1 means there is no association between products A and B. Lift of greater than 1 means products A and B are more likely to be bought together.
Finally, Lift of less than 1 refers to the case where two products are unlikely to be bought together.
For large sets of data, there can be hundreds of items in hundreds of thousands transactions.
The Apriori algorithm tries to extract rules for each possible combination of items.
For instance, Lift can be calculated for item 1 and item 2, item 1 and item 3, item 1 and item 4 and then item 2 and item 3, item 2 and item 4 and then combinations of items e.g. item 1, item 2 and item 3; similarly item 1, item2, and item 4, and so on.
As you can see from the above example, this process can be extremely slow due to the number of combinations. To speed up the process, we need to perform the following steps:
1. Set a minimum value for support and confidence. This means that we are only interested in finding rules for the items that have certain default existence (e.g. support) and have a minimum value for co-occurrence with other items (e.g. confidence).2. Extract all the subsets having higher value of support than minimum threshold.
3. Select all the rules from the subsets with confidence value higher than minimum threshold.
4. Order the rules by descending order of Lift.

Apriori Assignment
1) Implement a Java-based Apriori() function with specific interface and parameters;
2) For iMADE implementation, implement a multiagent based Apriori application.
In order to ensure a well defined multiagent system (on top of JADE platform), the application must at least consists of two (or more than 2 iMADE agents). E,g. Data-miner agent to get the data from the iMADE server, Apriori agent to perform the Apriori operations.
Apriori(transactions: Union[List[tuple], Callable], min_support: float = 0.5, min_confidence: float = 0.5, max_length: int = 8, verbosity: int = 0, output_transaction_ids: bool = False)
Parameters:
1) transactions (list of tuples, list of itemsets.TransactionWithId,) – or a callable returning a generator. Use TransactionWithId’s when the transactions have ids which should appear in the outputs. The transactions may be either a list of tuples, where the tuples must contain hashable items. Alternatively, a callable returning a generator may be passed. A generator is not sufficient, since the algorithm will exhaust it, and it needs to iterate over it several times. Therefore, a callable returning a generator must be passed.
2) min_support (float) – The minimum support of the rules returned. The support is frequency of which the items in the rule appear together in the data set.
3) min_confidence (float) – The minimum confidence of the rules returned. Given a rule X -> Y, the confidence is the probability of Y, given X, i.e. P(Y|X) = conf(X -> Y)
4) max_length (int) – The maximum length of the itemsets and the rules.
5) verbosity (int) – The level of detail printing when the algorithm runs. Either 0, 1 or 2.
6) output_transaction_ids (bool) – If set to true, the output contains the ids of transactions that contain a frequent itemset. The ids are the enumeration of the transactions in the sequence they appear.
Have you ever gone to a search engine, typed in a word or part of a word, and the search engine automatically completed the search term for you? Perhaps it recommended something you didn’t even know existed, and you searched for that instead. This requires a way to find frequent itemsets efficiently. FP-growth algorithm find frequent itemsets or pairs, sets of things that commonly occur together, by storing the dataset in a special structure called an FP-tree.
The FP-Growth Algorithm, proposed by Han in , is an efficient and scalable method for mining the complete set of frequent patterns by pattern fragment growth, using an extended prefix-tree structure for storing compressed and crucial information about frequent patterns named frequent-pattern tree (FP-tree). In his study, Han proved that his method outperforms other popular methods for mining frequent patterns, e.g. the Apriori Algorithm and the TreeProjection .
The FP-growth algorithm scans the dataset only twice. The basic approach to finding frequent itemsets using the FP-growth algorithm is as follows:
1 Build the FP-tree.
2 Mine frequent itemsets from the FP-tree.
The FP stands for “frequent pattern.” An FP-tree looks like other trees in computer science, but it has links connecting similar items. The linked items can be thought of as a linked list.
The FPtree is used to store the frequency of occurrence for sets of items. Sets are stored as paths in the tree.
Sets with similar items will share part of the tree.
Only when they differ will the tree split.
A node identifies a single item from the set and the number of times it occurred in this sequence.
A path will tell you how many times a sequence occurred.
The links between similar items, known as node links, will be used to rapidly find the location of similar items.
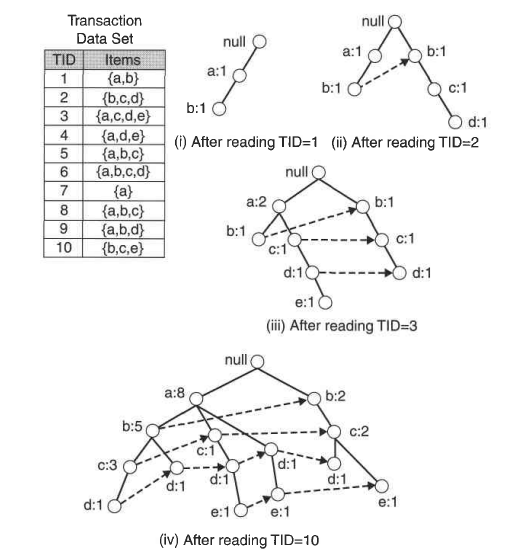
Pros: Usually faster than Apriori.
Cons: Difficult to implement; certain datasets degrade the performance.
Works with: Nominal values.
General approach to FP-growth algorithm
1. Collect: Any method.
2. Prepare: Discrete data is needed because we’re storing sets. If you have continuous data, it will
3. need to be quantized into discrete values.
4. Analyze: Any method.
5. Train: Build an FP-tree and mine the tree.
6. Test: Doesn’t apply.
7. Use: This can be used to identify commonly occurring items that can be used to make decisions, suggest items, make forecasts, and so on.

FP-growth Assignment
1) Implement a Java-based FP-growth() function with specific interface and parameters;
2) For iMADE implementation, implement a multiagent based FP-growth application.
In order to ensure a well defined multiagent system (on top of JADE platform), the application must at least consists of two (or more than 2 iMADE agents). E,g. Data-miner agent to get the data from the iMADE server, FP-growth agent to perform the FP-growth operations.
fpgrowth(transactions: Union[List[tuple], Callable], min_support=0.5, use_colnames=False, max_len=None, verbose=0)
1) transactions (list of tuples, list of itemsets.TransactionWithId,) – or a callable returning a generator. Use TransactionWithId’s when the transactions have ids which should appear in the outputs. The transactions may be either a list of tuples, where the tuples must contain hashable items. Alternatively, a callable returning a generator may be passed. A generator is not sufficient, since the algorithm will exhaust it, and it needs to iterate over it several times. Therefore, a callable returning a generator must be passed.
2) min_support : float (default: 0.5): A float between 0 and 1 for minimum support of the itemsets returned. The support is computed as the fraction transactions_where_item(s)_occur / total_transactions.
3) use_colnames : bool (default: False): If true, uses the datasets column names in the returned datasets instead of column indices.
4) max_len : int (default: None): Maximum length of the itemsets generated. If None (default) all possible itemsets lengths are evaluated.
5) verbose : int (default: 0): Shows the stages of conditional tree generation.
use Apriori and FP-growth to find the association of these items
/Public/Uploadfiles/20210421/20210421021308_88578.zip