
In previous modules, we talked about supervised learning topics. We are now ready to move on to unsupervised learning where our goals will be much different. In supervised learning, we tried to match inputs to some existing patterns. For unsupervised learning, we will try to discover patterns in raw, unlabeled data sets. We saw classification problems come up often in supervised learning and we will now examine a similar problem in unsupervised learning: clustering.
Clustering is the process of grouping similar data and isolating dissimilar data. We want the data points in clusters we come up with to share some common properties that separate them from data points in other clusters. Ultimately, we’ll end up with a number of groups that meet these requirements. This probably sounds familiar because on the surface it sounds a lot like classification. But be aware that clustering and classification solve two very different problems. Clustering is used to identify potential groups in a data set while classification is used to match an input to an existing group.
K-Means clustering attempts to divide a data set into K clusters using an iterative process. The first step is choosing a center point for each cluster. This center point does not need to correspond to an actual data point. The center points could be chosen at random or we could pick them if we have a good guess of where they should be. In the code below, the center points are chosen using the k-means++ method which is designed to speed up convergence. Analysis of this method is beyond the scope of this module but for additional initial options in sklearn, check here.
The second step is assigning each data point to a cluster. We do this by measuring the distance between a data point and each center point and choosing the cluster whose center point is the closest. This step is illustrated in Figure 2.
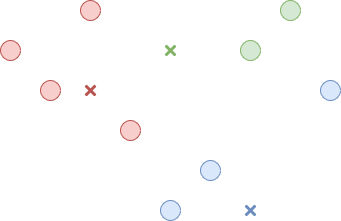
Figure 2. Associate each point with a cluster
Now that all the data points belong to a cluster, the third step is recomputing the center point of each cluster. This is just the average of all the data points belonging to the cluster. This step is illustrated in Figure 3.

Figure 3. Find the new center for each cluster
Now we just repeat the second and third step until the centers stop changing or only change slightly between iterations. The result is K clusters where data points are closer to their cluster’s center than any other cluster’s center. This is illustrated in Figure 4.

Figure 4. The final clusters
K-Means clustering requires us to input the number of expected clusters which isn’t always easy to determine. It can also be inconsistent depending on where we choose the starting center points in the first step. Over the course of the process, we may end up with clusters that appear to be optimized but may not be the best overall solution. In Figure 4, we end with a red data point that is equally far from the red center and the blue center. This stemmed from our initial center choices. In contrast, Figure 5 shows another result we may have reached given different starting centers and looks a little better.

Figure 5. An alternative set of clusters
On the other hand, K-Means is very powerful because it considers the entire data set at each step. It is also fast because we’re only ever computing distances. So if we want a fast technique that considers the whole data set and we have some knowledge of what the underlying groups might look like, K-Means is a good choice.
K-Means Assignment
1) Implement a Java-based K-Means() function with specific interface and parameters;
2) For iMADE implementation, implement a multiagent based K-Means application.
In order to ensure a well defined multiagent system (on top of JADE platform), the application must at least consists of two (or more than 2 iMADE agents). E,g. Data-miner agent to get the data from the iMADE server, K-Means agent to perform the K-Means operations.
1)n_clustersint, default=8
The number of clusters to form as well as the number of centroids to generate.
2)init{‘k-means++’, ‘random’}, callable or array-like of shape (n_clusters, n_features), default=’k-means++’ .
Method for initialization: ‘k-means++’ : selects initial cluster centers for k-mean clustering in a smart way to speed up convergence. See section Notes in k_init for more details. ‘random’: choose n_clusters observations (rows) at random from data for the initial centroids. If an array is passed, it should be of shape (n_clusters, n_features) and gives the initial centers. If a callable is passed, it should take arguments X, n_clusters and a random state and return an initialization.
3)n_initint, default=10.
Number of time the k-means algorithm will be run with different centroid seeds. The final results will be the best output of n_init consecutive runs in terms of inertia.
4) max_iterint, default=300.
Maximum number of iterations of the k-means algorithm for a single run.
5) tol: float, default=1e-4
Relative tolerance with regards to Frobenius norm of the difference in the cluster centers of two consecutive iterations to declare convergence.
6) precompute_distances{‘auto’, True, False}, default=’auto’
Precompute distances (faster but takes more memory).
‘auto’ : do not precompute distances if n_samples * n_clusters > 12 million. This corresponds to about 100MB overhead per job using double precision.
True : always precompute distances.
False : never precompute distances.
7) verboseint, default=0
Verbosity mode.
Determines random number generation for centroid initialization. Use an int to make the randomness deterministic.
When pre-computing distances it is more numerically accurate to center the data first. If copy_x is True (default), then the original data is not modified. If False, the original data is modified, and put back before the function returns, but small numerical differences may be introduced by subtracting and then adding the data mean. Note that if the original data is not C-contiguous, a copy will be made even if copy_x is False. If the original data is sparse, but not in CSR format, a copy will be made even if copy_x is False.
10) algorithm{“auto”, “full”, “elkan”}, default=”auto”K-means algorithm to use. The classical EM-style algorithm is “full”. The “elkan” variation is more efficient on data with well-defined clusters, by using the triangle inequality. However it’s more memory intensive due to the allocation of an extra array of shape (n_samples, n_clusters).
K-Means Application
K-Means Clustering (Annual Income/Spending Score) /Public/Uploadfiles/20210415/20210415090457_88627.zip