
Logistic regression is a method for binary classification. It works to divide points in a dataset into two distinct classes, or categories. For simplicity, let’s call them class A and class B. The model will give us the probability that a given point belongs in category B. If it is low (lower than 50%), then we classify it in category A. Otherwise, it falls in class B. It’s also important to note that logistic regression is better for this purpose than linear regression with a threshold because the threshold would have to be manually set, which is not feasible. Logistic regression will instead create a sort of S-curve (using the sigmoid function) which will also help show certainty, since the output from logistic regression is not just a one or zero. Here is the standard logistic function, note that the output is always between 0 and 1, but never reaches either of those values.

Logistic regression is great for situations where you need to classify between two categories. Some good examples are accepted and rejected applicants and victory or defeat in a competition. Here is an example table of data that would be a good candidate for logistic regression.
| Studying | Success | |
|---|---|---|
| Hours | Focused | Pass? |
| 1 | False | False |
| 3 | False | True |
| 0.5 | True | False |
| 2 | False | True |
Notice that the student’s success is determined by the inputs and the value is binary, so logistic regression will work well for this scenario.
Logistic regression works using a linear combination of inputs, so multiple information sources can govern the output of the model. The parameters of the model are the weights of the various features, and represent their relative importance to the result. In the equation that follows, you should recognize the formula used in linear regression. Logistic regression is, at its base, a transformation from a linear predictor to a probability between 0 and 1.
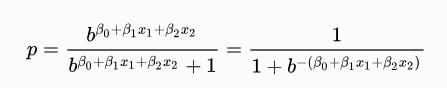
As in linear regression, the beta values are the weights and x values are the variable inputs. This formula gives the probability that the input belongs to Class B, which is the goal of the logistic regression model.
Until now, we’ve been discussing the situation where there are exactly two distinct outputs, for example a pass or a fail. But, what if there were more than two possible outputs? What about the number classification example, where the output can be any digit from 0 to 9?
Well, there is a way to handle that with logistic regression. When using the scikit-learn library, as the example code does, the facility is already there. With scikit-learn, you can use the multinomial mode and supply any number of classes in the training data. You can think of the method as creating multiple models and comparing their probabilities.
|
from sklearn.linear_model import LogisticRegression import numpy as np import random #defines the classification for the training data. def true_classifier(i): if i >= 700: return 1 return 0 #Generate a random dataset which includes random scores from 0 to 1000. x = np.array([ random.randint(0,1000) for i in range(0,1000) ]) #The model will expect a 2D array, so we must reshape #For the model, the 2D array must have rows equal to the number of samples, #and columns equal to the number of features. #For this example, we have 1000 samples and 1 feature. x = x.reshape((-1, 1)) #For each point, y is a pass/fail for the grade. The simple threshold is arbitrary, #and can be changed as you would like. Classes are 1 for success and 0 for failure y = [ true_classifier(x[i][0]) for i in range(0,1000) ] #Again, we need a numpy array, so we convert. y = np.array(y) #Our goal will be to train a logistic regression model to do pass/fail to the same threshold. model = LogisticRegression(solver='liblinear') #The fit method actually fits the model to our training data model = model.fit(x,y) #Create 100 random samples to try against our model as test data samples = [random.randint(0,1000) for i in range(0,100)] #Once again, we need a 2d Numpy array samples = np.array(samples) samples = samples.reshape(-1, 1) #Now we use our model against the samples. output is the probability, and _class is the class. _class = model.predict(samples) proba = model.predict_proba(samples) num_accurate = 0 #Finally, output the results, formatted for nicer viewing. #The format is []: Class, probability [] #So, the probability array is the probability of failure, followed by the probability of passing. #In an example run, [7]: Class 0, probability [ 9.99966694e-01 3.33062825e-05] #Means that for value 7, the class is 0 (failure) and the probability of failure is 99.9% for i in range(0,100): if (true_classifier(samples[i])) == (_class[i] == 1): num_accurate = num_accurate + 1 print("" + str(samples[i]) + ": Class " + str(_class[i]) + ", probability " + str(proba[i])) #skip a line to separate overall result from sample output print("") print(str(num_accurate) +" out of 100 correct.") |
In the example, scikit-learn and numpy are used to train a simple logistic regression model. The model is basic, but extensible. With logistic regression, more features could be added to the data set seamlessly, simply as a column in the 2D arrays.
The code creates a 2D array representing the training input, in this case it is 1000 x 1, since there are 1000 samples and 1 feature. These inputs are scores out of 1000. A training output array is also created, with the classification of 1 for pass and 0 for fail, based on a threshold. Then, scikit-learn’s LogisticRegression class is used to fit a logistic regression classifier to the data. After that, the next step is to test for accuracy with a different data set. So, we create another 100 random samples to test against, and predict against them using the model.
Why use logistic regression? Logistic regression is well suited to the case of binary classification, or classifying in 2 categories. Logistic regression is also a relatively simple method, utilizing a weighted sum of inputs, similar to linear regression. Logistic regression is also useful in that it gives a continuous value, representing the probability of a given classification being correct. For these reasons, advocates say that logistic regression should be the first thing learned in the data science world.
Logistic regression build upon linear regression by extending its use to classification. Although it is not able to classify into more than two classes, it is still effective in what it does, and simple to implement. Consider logistic regression as the first thought pass/fail method. When you just need a pass/fail probability from data, logistic regression is the simplest and likely best option.
Machine learning libraries make using Logistic Regression very simple. Check out the example code in the repository and follow along. The basic idea is to supply the training data as pairs of input and classification, and the model will be built automatically. As always, keep in mind the basics mentioned in the overview section of this repository, as there is no fool-proof method for machine learning.
Acknowledge: Python Machine Learning supervised by Amirsina Torfi, 2019.