
Have you ever gone to a search engine, typed in a word or part of a word, and the search engine automatically completed the search term for you? Perhaps it recommended something you didn’t even know existed, and you searched for that instead. This requires a way to find frequent itemsets efficiently. FP-growth algorithm find frequent itemsets or pairs, sets of things that commonly occur together, by storing the dataset in a special structure called an FP-tree.
The FP-Growth Algorithm, proposed by Han in , is an efficient and scalable method for mining the complete set of frequent patterns by pattern fragment growth, using an extended prefix-tree structure for storing compressed and crucial information about frequent patterns named frequent-pattern tree (FP-tree). In his study, Han proved that his method outperforms other popular methods for mining frequent patterns, e.g. the Apriori Algorithm and the TreeProjection .
The FP-growth algorithm scans the dataset only twice. The basic approach to finding frequent itemsets using the FP-growth algorithm is as follows:
1 Build the FP-tree.
2 Mine frequent itemsets from the FP-tree.
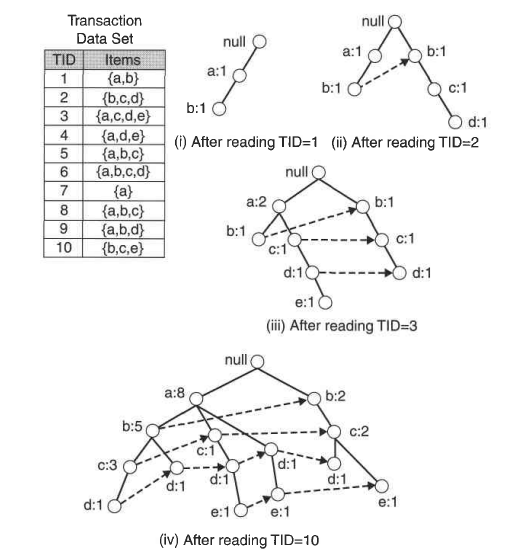
The FP stands for “frequent pattern.” An FP-tree looks like other trees in computer science, but it has links connecting similar items. The linked items can be thought of as a linked list.
The FPtree is used to store the frequency of occurrence for sets of items. Sets are stored as paths in the tree.
Sets with similar items will share part of the tree.
Only when they differ will the tree split.
A node identifies a single item from the set and the number of times it occurred in this sequence.
A path will tell you how many times a sequence occurred.
The links between similar items, known as node links, will be used to rapidly find the location of similar items.
Pros: Usually faster than Apriori.
Cons: Difficult to implement; certain datasets degrade the performance.
Works with: Nominal values.
General approach to FP-growth algorithm
1. Collect: Any method.
2. Prepare: Discrete data is needed because we’re storing sets. If you have continuous data, it will
3. need to be quantized into discrete values.
4. Analyze: Any method.
5. Train: Build an FP-tree and mine the tree.
6. Test: Doesn’t apply.
7. Use: This can be used to identify commonly occurring items that can be used to make decisions, suggest items, make forecasts, and so on.
1. Download and install Anaconda (distribution version) from Anaconda official site.

2. Choose your OS platform (Win / Mac / Linux) and download Anaconda installer.

3. Once the installation is completed. Launch the Anaconda Navigator.

Anaconda Navigator is a useful platform which contain all commonly used anaconda applications such as:
1. Spyder - Scientific python development environment IDE with advanced editing, interactive testing, debugging features.
2. Jupyter - Web-based, interactive computing environment. It allows edit and run human-readable docs while describing the data analysis.
3. JupyterLab - An extensible environment for interactive and reproducible computing, based on the Jupyter Notebook and Architecture.
Besides, Anaconda Environments function allow user to install different computation environments (default is "base (root)" environment ) via the installation of different conda python packages.
The following figure show the Anaconda platform with the installation of both "base root" and "tensorflow" environment which is used for Deep Learning Networks. We will talk about it in the future labs.
4. Launch the Spyder application by pressing the "Launch" button or run the Spyder application directly from the Windows menu. Like this.
(Note: If your Spyder haven't installed yet, press the "Install" button in the Anaconda Navigator platform. )

As shown in the above figure, Spyder allows us to open/view/edit/run any python program (Left) and the results will be shown on the Right, which is a typical command-line console.
Of course, we can also directly enter any commands and scripts in this console and run the python code directly.
In this lab, we will use these functions and features in this lab to run the FP-tree scripts.
Step 1 - Define the variables and treeNode class
In [1]:
|
#variables: #name of the node, a count #nodelink used to link similar items #parent vaiable used to refer to the parent of the node in the tree #node contains an empty dictionary for the children in the node class treeNode: def __init__(self, nameValue, numOccur, parentNode): self.name = nameValue self.count = numOccur self.nodeLink = None self.parent = parentNode #needs to be updated self.children = {} #increments the count variable with a given amount def inc(self, numOccur): self.count += numOccur #display tree in text. Useful for debugging def disp(self, ind=1): print (' '*ind, self.name, ' ', self.count) for child in self.children.values(): child.disp(ind+1) |
Step 2 - Define the Root node "Pyramid"
In [2]:
|
rootNode = treeNode('pyramid',9,None) |
Step 3 - Define the first child node "eye"
In [3]:
|
rootNode.children['eye'] = treeNode('eye',13,None) |
Step 4 - Display nodes
In [4]:
|
rootNode.disp() |
Output:
|
pyramid 9 eye 13 |
In addition to the FP-tree, you need a header table to point to the first instance of a given type. The header table will allow you to quickly access all of the elements of a given type in the FP-tree.
In addition to storing pointers, you can use the header table to keep track of the total count of every type of element in the FP-tree.
createTree(), takes the dataset and the minimum support as arguments and builds the FP-tree. This makes two passes through the dataset. The first pass goes through everything in the dataset and counts the frequency of each term. These are stored in the header table.
Step 5 - Create FP-tree
In [5]:
|
def createTree(dataSet, minSup=1): #create FP-tree from dataset but don't mine headerTable = {} #go over dataSet twice for trans in dataSet:#first pass counts frequency of occurance for item in trans: headerTable[item] = headerTable.get(item, 0) + dataSet[trans] for k in list(headerTable): #remove items not meeting minSup if headerTable[k] < minSup: del(headerTable[k]) freqItemSet = set(headerTable.keys()) #print 'freqItemSet: ',freqItemSet if len(freqItemSet) == 0: return None, None #if no items meet min support -->get out for k in headerTable: headerTable[k] = [headerTable[k], None] #reformat headerTable to use Node link #print 'headerTable: ',headerTable retTree = treeNode('Null Set', 1, None) #create tree for tranSet, count in dataSet.items(): #go through dataset 2nd time localD = {} for item in tranSet: #put transaction items in order if item in freqItemSet: localD[item] = headerTable[item][0] if len(localD) > 0: orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)] updateTree(orderedItems, retTree, headerTable, count)#populate tree with ordered freq itemset return retTree, headerTable #return tree and header table |
Step 6 - UpdateTree() grow the Fp-tree with an itemset.
In [6]:
|
def updateTree(items, inTree, headerTable, count): if items[0] in inTree.children:#check if orderedItems[0] in retTree.children inTree.children[items[0]].inc(count) #incrament count else: #add items[0] to inTree.children inTree.children[items[0]] = treeNode(items[0], count, inTree) if headerTable[items[0]][1] == None: #update header table headerTable[items[0]][1] = inTree.children[items[0]] else: updateHeader(headerTable[items[0]][1], inTree.children[items[0]]) if len(items) > 1:#call updateTree() with remaining ordered items updateTree(items[1::], inTree.children[items[0]], headerTable, count) |
Step 7 - UpdateHeader() makes sure the node links points to every instance of the this item on the tree
In [7]:
def updateHeader(nodeToTest, targetNode): #this version does not use recursion
while (nodeToTest.nodeLink != None): #Do not use recursion to traverse a linked list!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
Step 8 - Load sample data
In [8]:
|
def loadSimpDat(): simpDat = [['r', 'z', 'h', 'j', 'p'], ['z', 'y', 'x', 'w', 'v', 'u', 't', 's'], ['z'], ['r', 'x', 'n', 'o', 's'], ['y', 'r', 'x', 'z', 'q', 't', 'p'], ['y', 'z', 'x', 'e', 'q', 's', 't', 'm']] return simpDat |
Step 9 - The createTree() function doesn’t take the input data as lists. It expects a dictionary with the itemsets as the dictionary keys and the frequency as the value. A createInitSet() function does this conversion for you.
In [9]:
|
def createInitSet(dataSet): retDict = {} for trans in dataSet: retDict[frozenset(trans)] = 1 return retDict |
Step 10 - Load Sample Data
In [10]:
|
simpDat = loadSimpDat() |
Step 11 - Display Sample Data
In [11]:
simpDat
Output:
Out[11]:
[['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
Step 12 - Create InitSet
In [12]:
initSet = createInitSet(simpDat)
Step 13 - Display InitSet
In [13]:
|
initSet |
Output:
Out[13]:
{frozenset({'h', 'j', 'p', 'r', 'z'}): 1,
frozenset({'s', 't', 'u', 'v', 'w', 'x', 'y', 'z'}): 1,
frozenset({'z'}): 1,
frozenset({'n', 'o', 'r', 's', 'x'}): 1,
frozenset({'p', 'q', 'r', 't', 'x', 'y', 'z'}): 1,
frozenset({'e', 'm', 'q', 's', 't', 'x', 'y', 'z'}): 1}
Step 14 - Create FP Tree - myFPtree
In [14]:
|
#The FP-tree myFPtree, myHeaderTab = createTree(initSet, 3) |
Step 15 - Display myFPtree
In [15]:
myFPtree.disp() |
|
Null Set 1 z 5 r 1 x 3 t 3 y 3 s 2 r 1 x 1 s 1 r 1 |
Mining frequent items from an FP-tree
There are three basic steps to extract the frequent itemsets from the FP-tree:
1 Get conditional pattern bases from the FP-tree.
2 From the conditional pattern base, construct a conditional FP-tree.
3 Recursively repeat steps 1 and 2 on until the tree contains a single item.
The conditional pattern base is a collection of paths that end with the item you’re looking for.
Each of those paths is a prefix path. In short, a prefix path is anything on the tree between the item you’re looking for and the tree root.
ascendTree(), which ascends the tree, collecting the names of items it encounters
Step 16 - Define ascendTree
In [16]:
def ascendTree(leafNode, prefixPath): #ascends from leaf node to root if leafNode.parent != None: prefixPath.append(leafNode.name) ascendTree(leafNode.parent, prefixPath) |
The findPrefixPath() function iterates through the linked list until it hits the end.
For each item it encounters, it calls ascendTree().
This list is returned and added to the conditional pattern base dictionary called condPats.
Step 17 - Define findPrefixPath
In [17]:
|
def findPrefixPath(basePat, treeNode): #treeNode comes from header table condPats = {} while treeNode != None: prefixPath = [] ascendTree(treeNode, prefixPath) if len(prefixPath) > 1: condPats[frozenset(prefixPath[1:])] = treeNode.count treeNode = treeNode.nodeLink return condPats |
Step 18 - Execute findPrefixPath for 'x'
In [18]:
|
findPrefixPath('x', myHeaderTab['x'][1]) |
|
Out[18]: {frozenset({'z'}): 3} |
Step 19 - Execute findPrefixPath for 'r'
In [19]:
findPrefixPath('r', myHeaderTab['r'][1])
Output:
|
Out[19]: {frozenset({'z'}): 1, frozenset({'s', 'x'}): 1, frozenset({'t', 'x', 'y', 'z'}): 1} |
The FP-growth algorithm is an efficient way of finding frequent patterns in a dataset.
The FP-growth algorithm works with the Apriori principle but is much faster.
The Apriori algorithm generates candidate itemsets and then scans the dataset to see if they’re frequent.
FP-growth is faster because it goes over the dataset only twice.
The dataset is stored in a structure called an FP-tree.
After the FP-tree is built, you can find frequent itemsets by finding conditional bases for an item and building a conditional FP-tree.
This process is repeated, conditioning on more items until the conditional FPtree has only one item.